I just wrote my first (and probably last) neural net program. That got
me down into the depths of how these things function.
A couple of friends asked me about how neural nets differ from
regular programming, so I'm going to geek out.
A neural net is a set of layers, each of which is a set of nodes.
Each node is pretty simple. It's a math function that accepts one
input and delivers one output. The trick is the equation that
the function evaluates.
A trivial neural net is three layers with one node on each layer. That's
one input layer, one translation layer, and one output layer.
As a rule, when you implement a neural net, there is also one 'bias'
node on every layer. The bias node shifts the curve defined by the
math function positive or negative.
This simple one-layer, one-node network can be used to convert
0 to 1 and 1 to 0.
We can do this with a node function that's just "multiply by this number"
and a bias of "and then add this".
One AI that works is an input node of "Multiply by -1 and a bias of
add 0" and the translation layer is "Multiply by 1 and add 1".
| Node Type
| Multiply by
| Add bias |
| Input |
-1 |
0 |
| Transition |
1 |
1 |
Output |
1 |
0 |
When the input node receives a 1, it's multiplied by -1, becoming -1.
Then it adds zero and passes -1 to the next node. The transition nodes
multiplies -1 by 1 (staying -1) and adds 1, giving a zero: a false
condition for testing if the input was zero.
If you feed it a zero, that's multiplied by -1, giving zero, and the bias
node adds zero, so zero is passed to the translation node. The translation
node multiplies the zero by one, giving zero, and then adds one for the
bias, ending up with 1, a "true" for testing if the input is zero.
In the real world, the node functions are more complex, and you have way
more than one node per layer, and lots of layers. The phrase you see in
AI discussions is "Deep Learning", the "Deep" refers to the neural net
being many layers deep.
For my really simple example, I worked out a set of multipliers and
biases to give the results I wanted.
In the real world, you have a known set of results from a given set of
inputs. You feed these inputs to the network and "train" the network to
provide the expected outputs.
To train my little play neural net, I assigned random numbers to the
multiplier and bias, calculated the results with a zero input and a one
input, then tested to see how close the result was to what I wanted. My
program generated 100,000 random numbers and selected the ones that came
closest to returning 0 when the input was 1 and returning 1 when the
input was zero.
It did not come up with the values I worked out by hand. It
ended up with this set of values:
| Node Type
| Multiply by
| Add bias |
| Input |
1.1 |
1.24 |
| Transition |
-.8 |
1.9 |
Output |
1 |
0 |
This set of values returns a .03 when a 1 is input (instead of
exactly zero) and 0.91 when a zero is input.
That's the strength and weakness of neural nets. They will work out
values that return the almost exactly the expected results. As W. said:
there you go with those fuzzy numbers.
But fuzzy numbers can be good. You don't want a pure true or false for
cancer screening. By the time cancer test reaches a "Yup, no doubt about
it," level, they're doing an autopsy. You really want a fuzzy "Not sure,
but it looks iffy. Let's take a sample and biopsy it."
When there's more than one node on a layer, every node on each layer
is connected to every node on the next layer. You end up taking the
sum of every node's output to send to all the nodes on the next
layer.
The complexity quickly goes beyond my ability to visualize it.
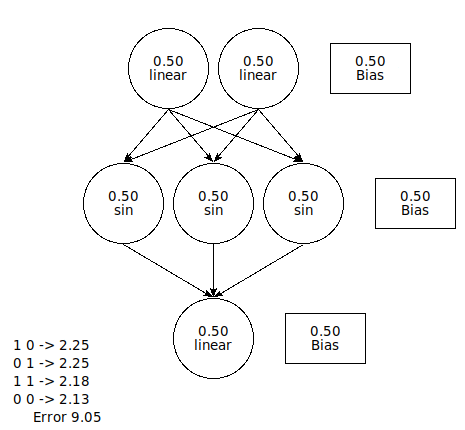
You can construct a network that will perform a logical OR
operation with six nodes. A logical OR operation is a function
that accepts two inputs and returns a "1" if either of the inputs is
"1" and returns "0" if both inputs are zero.
This network uses a sin() function to calculate the value of each
node. Instead of multiplying by the input, it multiplies by the
sin of the input value. This forces the output to be between 0 and 1.
Here's what the network looks like when all the nodes and biases are
initialized to 0.5.
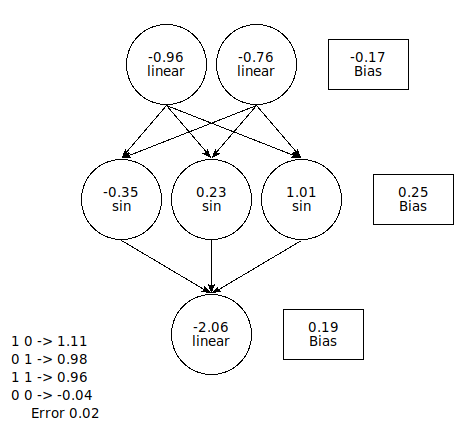
After a few hundred rounds of training, the network looks like this,
and the outputs are pretty close to correct.
The network I used to determine sentence types was 25 nodes on two
translation layers. Every one of those 50 nodes (plus the 20 input
nodes) has a different function associated with it.
That particular problem can't be solved with one layer. It gives
good results with 2 layers and gets worse and worse as you add
more layers.
That's a common problem with neural nets - figuring out how many
nodes and how many layers are optimal. The best advice I find on the
net is "guess" - or "try them all and see which one works."